TL;DR: Lombard effect can be applied to Voice Conversion and Text-to-speech to make the synthetic voice more understandable in noise.
Have you ever wondered why we tend to speak louder in a noisy room? Well, speech and linguistic researchers have been curious too, and they’ve explored a concept called the Lombard Effect (discovered by Étienne Lombard).
💬 The Lombard Effect in a Nutshell
Picture yourself at a party, where the music is playing and everyone is chatting and laughing. Having a good time! To make yourself heard by your friend, your brain automatically level up your voice’s volume, tweaks your pitch and even adjust your speech speed. What’s interesting is that we also tend to adapt our voice according to the feedback we get from the person in front of us and the noise around us to make sure they get the message.
Now, think about this effect applied to technology, like Text-to-Speech (TTS) systems, designed to make synthetic voices more intelligible. Imagine if these TTS systems could mimic the Lombard Effect. What if Alexa or Google Home could speak like that ? (A scenario already imagined by SNL).
🔊 Lombard Effect and Text-to-speech
Several works (See [1],[2]) explored how Lombard style could be applied to Text to Speech to improve intelligibility. Their goal was to see whether they could train on a voice with Lombard-style recordings and improve intelligibility and naturalness. They found that indeed it was a more natural way to improve intelligibility than signal processing!
▴ Why This Matters
Instead of just increasing the volume of processing the signal on the receiving end (like most hearing aids do), we can make the speech sound clearer right at the source!
Hearing aids are amazing pieces of engineering, but they come with their challenges. They’re not always comfortable, can be costly, and some people even opt not to use them regularly. But with Lombard-style TTS, the speech is automatically adjusted to be more distinct and easy to understand. This could be a game-changer, not only for those with hearing aids but for non-native-speakers (See [3]) and anyone in a noisy environment!
🚩 Current Problem
The works mentioned earlier used datasets with a lot of audio samples for a specific voice. What happens when you don’t have that? How can we synthesise voice in a Lombard style without having to record (tiring, time consuming and expensive for voice talents)?
🔍 A Solution?
Voice conversion, the process of transferring somebody’s voice onto recordings of someone else’s speech, can be applied as a data augmentation approach. The idea is to create recordings of the person’s voice in the Lombard style by transferring the speaker identity on to the Lombard speech recordings.
📚 Our Study
In a paper we recently presented at the Clarity Workshop at Interspeech 23’, we decided to investigate how we could preserve the Lombard effect when doing voice conversion. Indeed, the target speaker information might overtake the the Lombard effect characteristics and not give us the expected results. We want to answer the following question: Can we preserve Lombard-speaking style responsible for intelligibility during Voice Conversion, while also transferring the speaker’s identity?
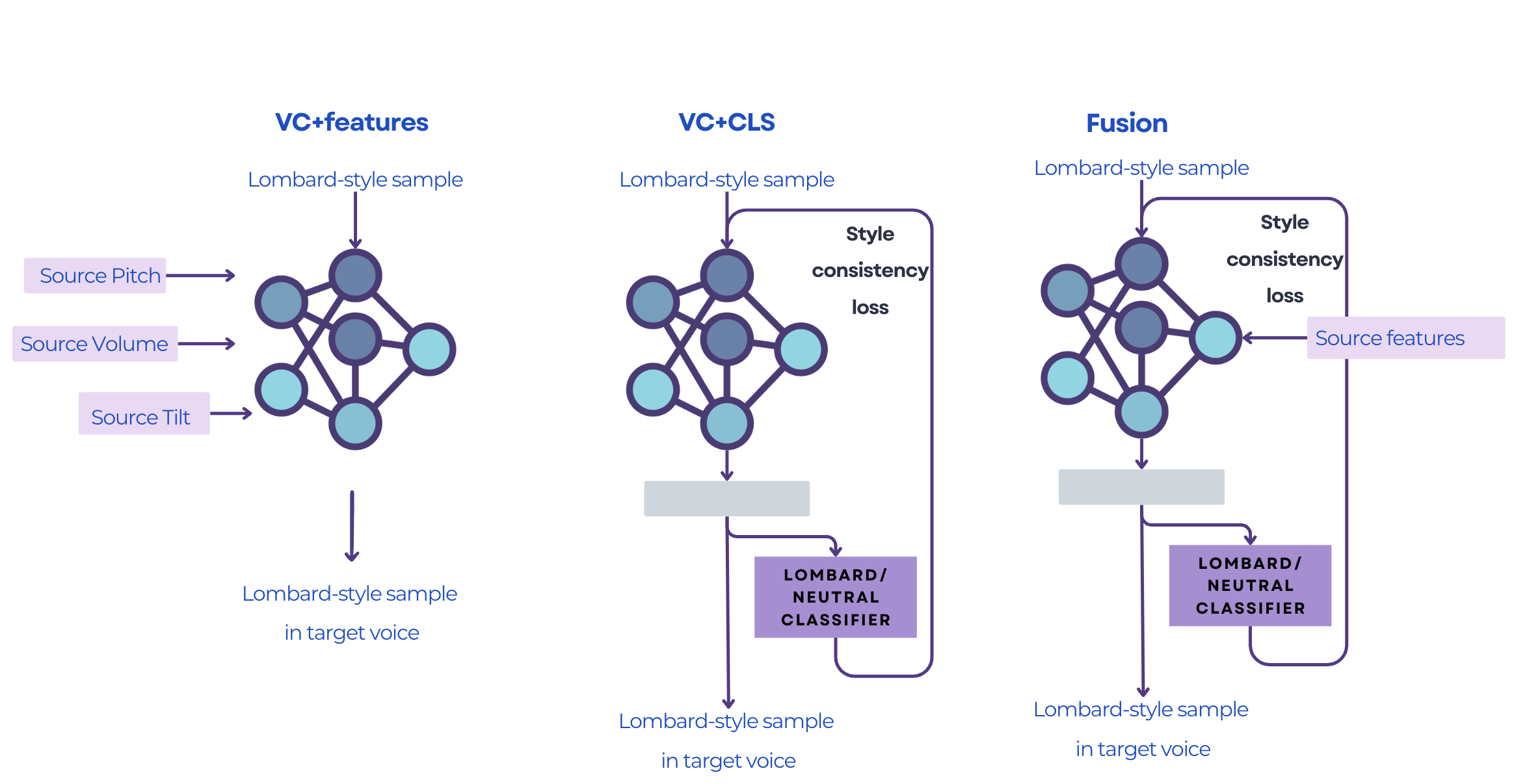
Here on the graphics below you can find the three systems we tried out in our experiments.
-
VC+features (Explicit Conditioning): We first decided to isolate three keys elements of the voice : pitch, volume and tilt. We then directly give the extracted features to the model. We then extract them on the Lombard recordings and give them to the voice conversion model to force it to keep them in the final recording, while also transferring the voice we want to transfer.
-
VC+CLS (Implicit Conditioning): What if we want the model to learn the features by itself? We tested this by adding a style classifier that forces the model to keep the source style after voice conversion. This setting helps to preserve the Lombard style without any nitpicking of features on our side.
-
Fusion: This system basically combines both worlds with the carefully selected features and the classifier forcing the model to keep the original speaking style.
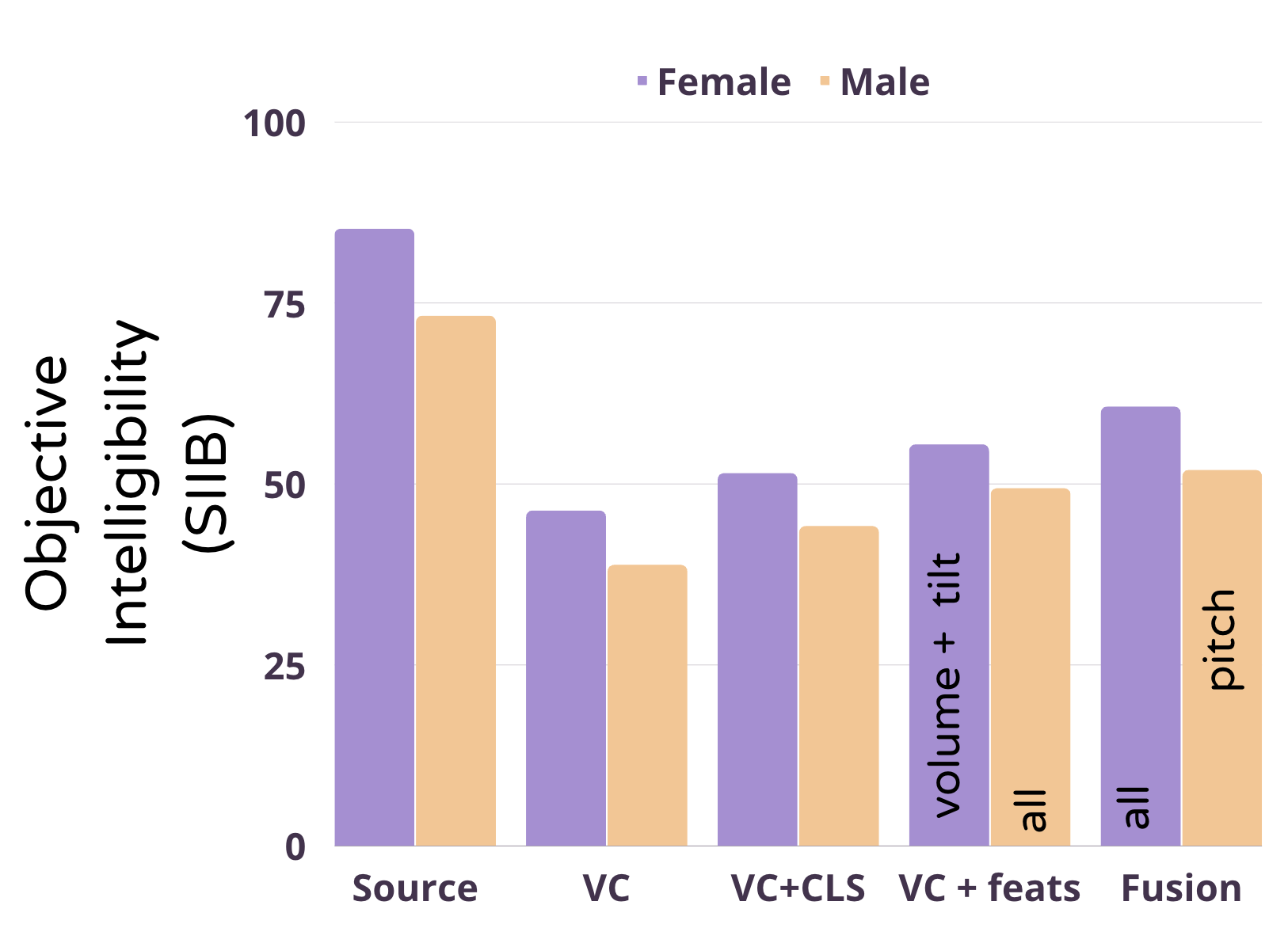
What did we find? As shown on the barplot below showing the intelligibility in high levels of noise, we found that
- Indeed Lombard effect is lost during conversion
- Both explicit and Implicit conditioning help to improve the final intelligibility
- The fusion works even better but loses the target speaker’s information making it less useful
- Different features worked better for female and male voices
👉 What’s the conclusion?
Past studies and our work show that Lombard-style TTS indeed increases speech intelligibility in noisy surroundings. While the naturalness might take a hit, it is less noticeable in noise and the speakers’ identity is not as affected. In our study, we found that the Lombard intelligibility effect is lost with basic Voice conversion but by using conditioning either implicitly or explicitly we are able to transfer them better!
Check out our paper here for more details
🚀 The Future of Intelligible Speech
Imagine a world where speech synthesis mimics our natural adjustments, making communication smoother in noisy places. With more research and innovation, Lombard-style TTS could help with everyday activities for people with hearing impairment such as listening to music, YouTube videos, watching movies, etc.,… and improve our interactions with smart assistants and voice-activated devices!
References
- [1] Bollepalli, Bajibabu, et al. “Normal-to-Lombard adaptation of speech synthesis using long short-term memory recurrent neural networks. Speech Communication 110 (2019)
- [2] Paul, Dipjyoti, et al. “Enhancing speech intelligibility in text-to-speech synthesis using speaking style conversion.” Proc. Interspeech (2020).
- [3] Marcoux, Katherine, et al. “The Lombard intelligibility benefit of native and non-native speech for native and non-native listeners.” Speech Communication 136 (2022)